Abstract

Monocular video human mesh recovery is essential for digital humans, avatar animation, and embodied
simulation, where both temporal stability and expressive whole-body motion are required. Existing video HMR
methods produce coherent body motion but often overlook detailed hand articulation, while image-based
whole-body methods recover SMPL-X meshes independently per frame, often leading to jittery and inaccurate
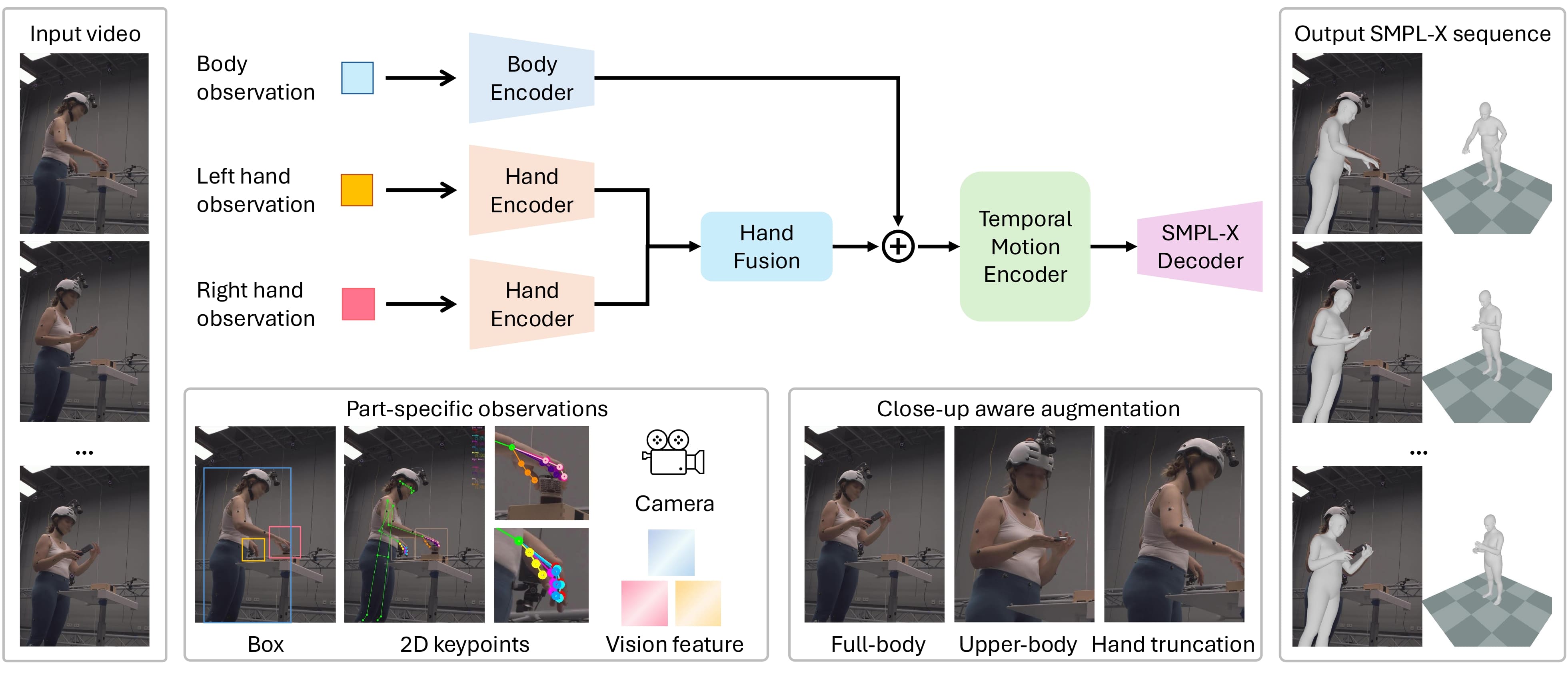
hand motion. We present DanceHMR, a temporally coherent whole-body HMR framework for challenging
in-the-wild monocular videos. DanceHMR unifies body context and part-specific hand observations through
residual body-hand fusion, enabling stable body motion and detailed hand recovery within a single temporal
architecture. We further introduce close-up-aware augmentation to improve robustness under upper-body
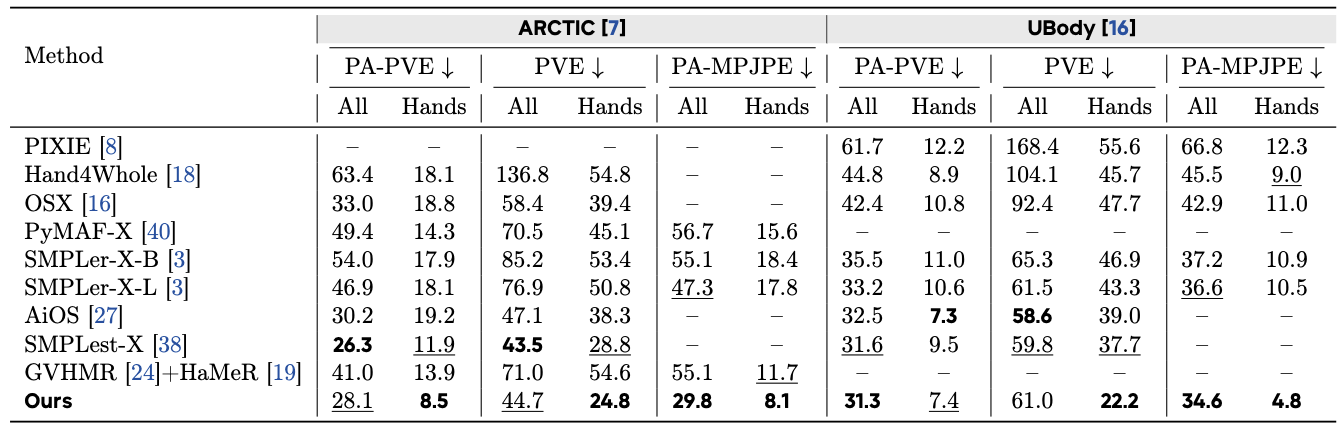
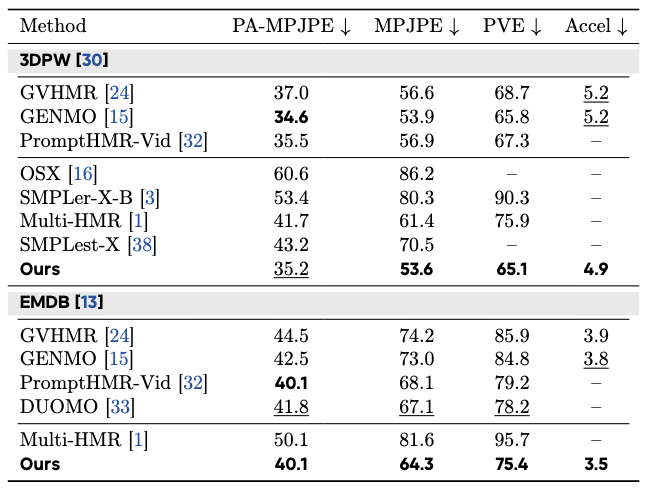
framing. Experiments on whole-body and body-only benchmarks demonstrate improved hand reconstruction,
competitive body accuracy, and temporally stable, 2D-consistent SMPL-X motion in real-world videos.